"V-JEPA 2 is a significant advancement that enables computer systems to develop a nuanced understanding of their environments, improving their response mechanisms."
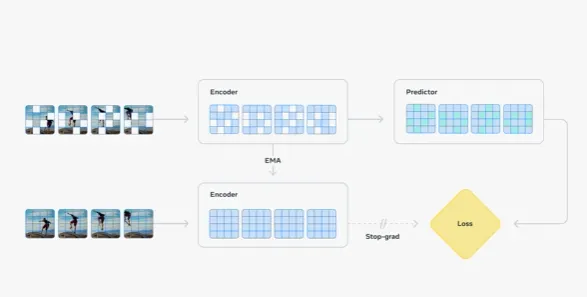
"By training V-JEPA 2 using video, we've enabled the model to learn physical world interactions, which enhances robotics capabilities in perception and task execution."
The article discusses V-JEPA 2, a model developed by Meta that enables computer systems to better understand their environments and predict outcomes based on actions. By utilizing video, V-JEPA 2 learns important physical interactions, allowing robots to perform complex tasks such as picking up and placing objects. The advancements signify a promising step toward creating machines that may one day achieve human-level intelligence, with the AI community divided on timelines for such developments. Meta's increased compute power positions it well for future breakthroughs in systematic intelligence.
Read at Social Media Today
Unable to calculate read time
Collection
[
|
...
]