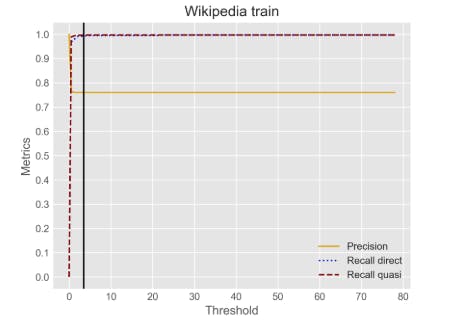
"Many text sanitization approaches simply operate by masking all detected PII spans. This may, however, lead to overmasking, as the actual risk of re-identification may vary greatly from one span to another."
"In many documents, a substantial fraction of the detected text spans may be kept in clear text without notably increasing the reidentification risk. For instance, in the TAB corpus, only 4.4 % of the entities were marked by the annotators as direct identifiers."
The article discusses the limitations of conventional text sanitization methods that often mask all detected personally identifiable information (PII). It highlights the problem of overmasking, where significant portions of text are unnecessarily obscured. Through the evaluation of the Text Anonymization Benchmark (TAB) corpus, the authors illustrate that a large percentage of text spans can be preserved without raising the risk of re-identification. The need for advanced privacy-oriented techniques in natural language processing (NLP) that balance privacy and usability is emphasized.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]