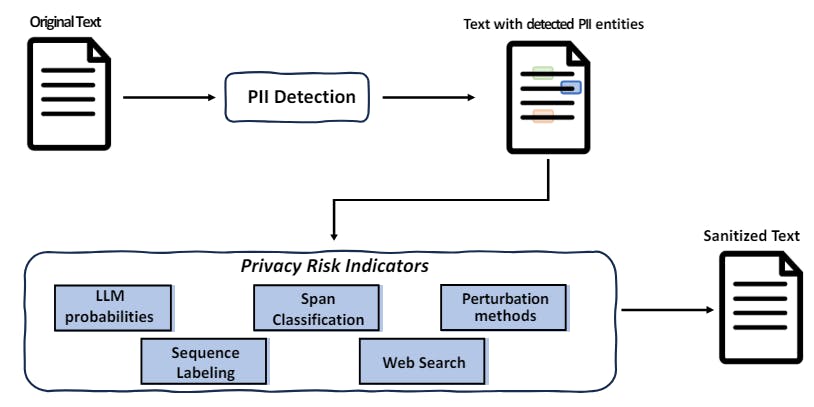
"Text sanitization is critical in concealing personal identifiers, ensuring privacy while analyzing text data. The study evaluates a two-step sanitization approach's efficacy on various datasets."
"This paper presents a comprehensive evaluation of privacy risk indicators for text anonymization, focusing on the performance and impact of different privacy-preserving techniques applied in natural language processing."
The paper discusses a two-step approach to text sanitization, aimed at concealing personal identifiers in documents to ensure privacy. It evaluates the effectiveness of this approach across two recent datasets: the Text Anonymization Benchmark and Wikipedia biographies. The authors analyze the empirical performance of their methods and examine privacy risk indicators relevant to natural language processing, detailing various experimental results and future work needed to advance privacy-preserving data techniques further.
#text-sanitization #privacy-preservation #natural-language-processing #data-security #anonymization-techniques
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]