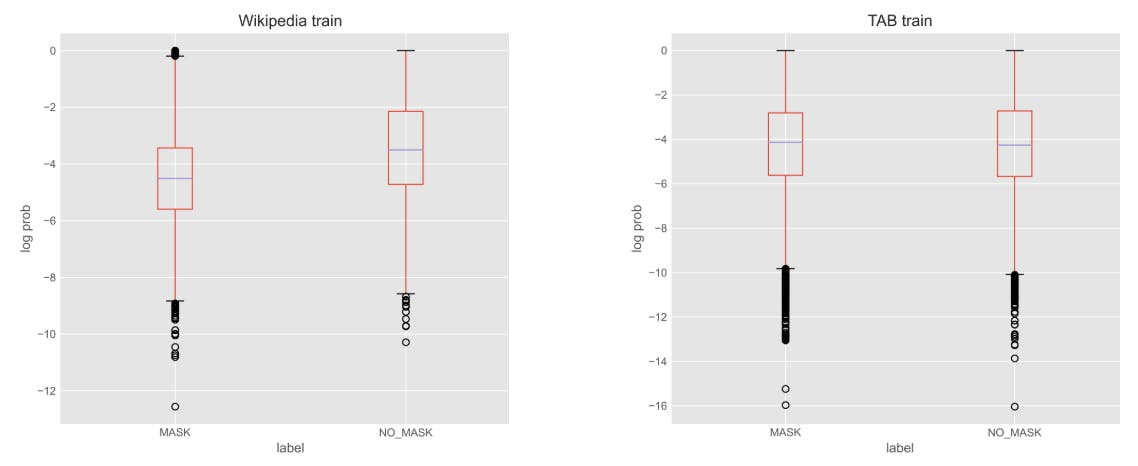
"The evaluation of privacy risk indicators across datasets indicates a significant correlation between human-labeled PII spans and model predictions, emphasizing the relevance of human judgment in privacy detection."
"Training on diverse datasets such as Wikipedia and the Text Anonymization Benchmark (TAB) enhances the performance of privacy-preserving techniques, showcasing the importance of robust training sources."
"Employing LLM probabilities and span classification methods led to promising results, indicating their potential effectiveness in identifying sensitive information within text."
"The combination of risk indicators from different techniques shows a complementary effect, further refining the analysis of privacy risks in Natural Language Processing."
This article examines the evaluation of privacy risk indicators in Natural Language Processing (NLP), specifically focusing on the effectiveness of various techniques to detect personally identifiable information (PII). By training models on diverse datasets such as Wikipedia and the Text Anonymization Benchmark (TAB), the study demonstrates that certain methods, including LLM probabilities and span classification, significantly improve PII detection. Results further suggest that combining multiple privacy risk indicators can enhance the accuracy of identifying privacy concerns, underscoring the value of human judgment in these assessments.
#privacy-risk-indicators #natural-language-processing #data-anonymization #differential-privacy #entity-recognition
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]