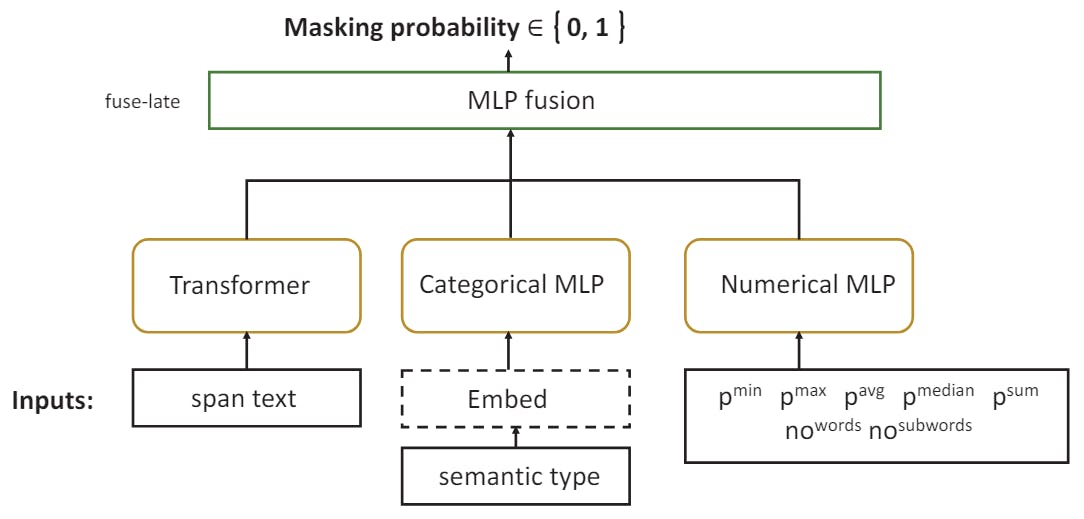
"The proposed method enhances the privacy risk assessment of text spans by incorporating vector representations to improve predictions on high-risk data."
"This research emphasizes the necessity of integrating context with numerical predictions to effectively mask sensitive information in text data."
"By utilizing advanced NLP techniques, our study addresses pressing privacy concerns associated with personal identifiable information, highlighting the need for effective data anonymization."
"Evaluating privacy risks involves a combination of LLM probabilities and contextual information to identify spans that require masking, thereby bolstering data protection."
The article discusses advancements in privacy-preserving data methodologies, focusing on the integration of context within NLP predictive models to enhance privacy risk assessments. By employing vector representations of text spans, the study aims to effectively identify and mask high-risk sensitive information, particularly personal identifiable information (PII). The findings underscore the importance of contextual data in evaluating privacy risks, advocating for a more comprehensive approach to data anonymization in language technologies. This research contributes to ongoing efforts in mitigating privacy concerns in an increasingly data-driven landscape.
#privacy-preservation #natural-language-processing #data-anonymization #entity-recognition #sensitive-information
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]